eDiscovery Daily Blog
eDiscovery Blog Throwback Thursdays – How Databases Were Built, Circa Early 1980s, Part 2
The Throwback Thursday blog two weeks ago included discussion of the first stages in a database-building project (circa 1980), including designing and planning a database, and preparing for a project. The next steps are described here. But first, if you missed the earlier posts in this series, they can be found here, here, here, here and here.
Establishing an Archive: Litigation teams shipped paper documents to be coded to a service provider, and the service provider’s first step was ‘logging documents in’ and establishing a project archive. Pages were numbered (if that hadn’t already been done) and put into sequentially numbered file folders, each bearing a label with the document number range. Those files were placed into boxes, which were also sequentially numbered, each of which had a big label on the front with the range of inclusive files, and the range of inclusive document numbers.
Logs were created that were used to track a folder’s progress through the project (those logs also meant we could locate any document at any time, because the log told us where the document was at any point in time). Here are sample log entries for a few folders of documents:
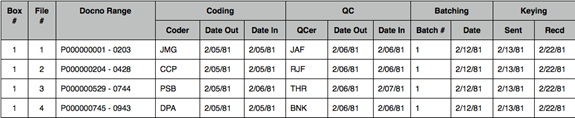
Note, this sample is a little misleading: logs were filled in by hand, by an archive librarian.
Coding and QC: Folders of documents were distributed to ‘coders’ who recorded information for each document – using a pencil and paper coding form that had pre-printed field names and spaces for recording information by hand. When a coder finished coding all the documents in a folder, the coding forms were put in the front of the folder, the folder was turned back into the archive, and the next folder was checked out. The same process was used for qc (quality control) – the documents and coding forms were reviewed by a second person to ensure that the coding was correct and that nothing was missed.
As project managers, we kept very detailed records on progress so that we could monitor where things stood with regard to schedule and budget. At the end of every workday, each coder and qcer recorded the number of hours worked that day and the number of documents and pages completed in that day. An archive librarian compiled these statistics for the entire coding and qc staff, and on a daily basis we calculated the group’s coding and qc rates and looked at documents / pages completed and remaining so that we could make adjustments if we were getting off schedule.
In next week’s post, we’ll look at the next steps in a database-building project.
Please let us know if there are eDiscovery topics you’d like to see us cover in eDiscoveryDaily.
Disclaimer: The views represented herein are exclusively the views of the author, and do not necessarily represent the views held by CloudNine Discovery. eDiscoveryDaily is made available by CloudNine Discovery solely for educational purposes to provide general information about general eDiscovery principles and not to provide specific legal advice applicable to any particular circumstance. eDiscoveryDaily should not be used as a substitute for competent legal advice from a lawyer you have retained and who has agreed to represent you.