eDiscovery Daily Blog
This Study Discusses the Benefits of Including Metadata in Machine Learning for TAR: eDiscovery Trends
A month ago, we discussed the Discovery of Electronically Stored Information (DESI) workshop and the papers describing research or practice presented at the workshop that was held earlier this month and we covered one of those papers a couple of weeks later. Today, let’s cover another paper from the study.
The Role of Metadata in Machine Learning for Technology Assisted Review (by Amanda Jones, Marzieh Bazrafshan, Fernando Delgado, Tania Lihatsh and Tamara Schuyler) attempts to study the role of metadata in machine learning for technology assisted review (TAR), particularly with respect to the algorithm development process.
Let’s face it, we all generally agree that metadata is a critical component of ESI for eDiscovery. But, opinions are mixed as to its value in the TAR process. For example, the Grossman-Cormack Glossary of Technology Assisted Review (which we covered here in 2012) includes metadata as one of the “typical” identified features of a document that are used as input to a machine learning algorithm. However, a couple of eDiscovery software vendors have both produced documentation stating that “machine learning systems typically rely upon extracted text only and that experts engaged in providing document assessments for training should, therefore, avoid considering metadata values in making responsiveness calls”.
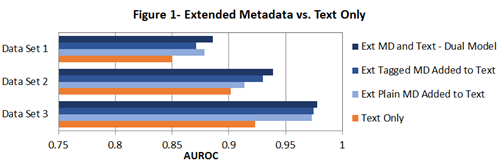
So, the authors decided to conduct a study that established the potential benefit of incorporating metadata into TAR algorithm development processes, as well as evaluate the benefits of using extended metadata and also using the field origins of that metadata. Extended metadata fields included Primary Custodian, Record Type, Attachment Name, Bates Start, Company/Organization, Native File Size, Parent Date and Family Count, to name a few. They evaluated three distinct data sets (one drawn from Topic 301 of the TREC 2010 Interactive Task, two other proprietary business data sets) and generated a random sample of 4,500 individual documents for each (split into a 3,000 document Control Set and a 1,500 document Training Set).
The metric they used throughout to compare model performance is Area Under the Receiver Operating Characteristic Curve (AUROC). Say what? According to the report, the metric indicates the probability that a given model will assign a higher ranking to a randomly selected responsive document than a randomly selected non-responsive document.
As indicated by the graphic above, their findings were that incorporating metadata as an integral component of machine learning processes for TAR improved results (based on the AUROC metric). Particularly, models incorporating Extended metadata significantly outperformed models based on body text alone in each condition for every data set. While there’s still a lot to learn about the use of metadata in modeling for TAR, it’s an interesting study and start to the discussion.
A copy of the twelve page study (including Bibliography and Appendix) is available here. There is also a link to the PowerPoint presentation file from the workshop, which is a condensed way to look at the study, if desired.
So, what do you think? Do you agree with the report’s findings? Please share any comments you might have or if you’d like to know more about a particular topic.
Disclaimer: The views represented herein are exclusively the views of the author, and do not necessarily represent the views held by CloudNine. eDiscovery Daily is made available by CloudNine solely for educational purposes to provide general information about general eDiscovery principles and not to provide specific legal advice applicable to any particular circumstance. eDiscovery Daily should not be used as a substitute for competent legal advice from a lawyer you have retained and who has agreed to represent you.