eDiscovery Best Practices: EDRM Data Set for Great Test Data
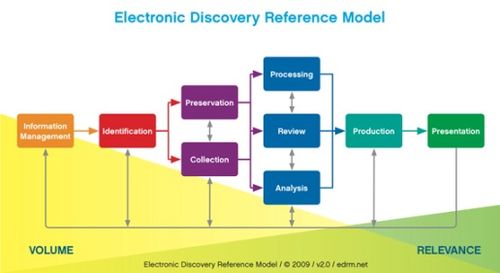
In it’s almost six years of existence, the Electronic Discovery Reference Model (EDRM) Project has implemented a number of mechanisms to standardize the practice of eDiscovery. Having worked on the EDRM Metrics project for the past four years, I have seen some of those mechanisms implemented firsthand.
One of the most significant recent accomplishments by EDRM is the EDRM Data Set. Anyone who works with eDiscovery applications and processes understands the importance to be able to test those applications in as many ways as possible using realistic data that will illustrate expected results. The use of test data is extremely useful in crafting a defensible discovery approach, by enabling you to determine the expected results within those applications and processes before using them with your organization’s live data. It can also help you identify potential anomalies (those never occur, right?) up front so that you can be proactive to develop an approach to address those anomalies before encountering them in your own data.
Using public domain data from Enron Corporation (originating from the Federal Energy Regulatory Commission Enron Investigation), the EDRM Data Set Project provides industry-standard, reference data sets of electronically stored information (ESI) to test those eDiscovery applications and processes. In 2009, the EDRM Data Set project released its first version of the Enron Data Set, comprised of Enron e-mail messages and attachments within Outlook PST files, organized in 32 zipped files.
This past November, the EDRM Data Set project launched Version 2 of the EDRM Enron Email Data Set. Straight from the press release announcing the launch, here are some of the improvements in the newest version:
- Larger Data Set: Contains 1,227,255 emails with 493,384 attachments (included in the emails) covering 151 custodians;
- Rich Metadata: Includes threading information, tracking IDs, and general Internet headers;
- Multiple Email Formats: Provision of both full and de-duplicated email in PST, MIME and EDRM XML, which allows organizations to test and compare results across formats.
The Text REtrieval Conference (TREC) Legal Track project provided input for this version of the data set, which, as noted previously on this blog, has used the EDRM data set for its research. Kudos to John Wang, Project Lead for the EDRM Data Set Project and Product Manager at ZL Technologies, Inc., and the rest of the Data Set team for such an extensive test set collection!
So, what do you think? Do you use the EDRM Data Set for testing your eDiscovery processes? Please share any comments you might have or if you’d like to know more about a particular topic.






