eDiscovery Trends: EDRM Metrics Privilege Survey
As a member of the EDRM Metrics Project for the past four years, I have seen several accomplishments by the group to provide an effective means of measuring the time, money and volumes associated with eDiscovery activities, including:
- Code Set: An extensive code set of activities to be tracked from Identification through Presentation, as well as Project Management.
- Case Study: A hypothetical case study that illustrates at each phase why metrics should be collected, what needs to be measured, how metrics are acquired and where they’re recorded, and how the metrics can be used.
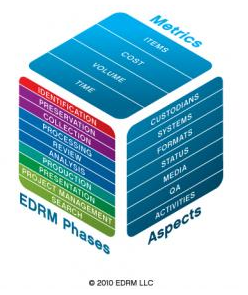
- Cube: A simple graphical model which illustrates the EDRM phases, aspects to be tracked (e.g., custodians, systems, media, QA, activities, etc.) and the metrics to be applied (i.e., items, cost, volume, time).
The EDRM Metrics project has also been heavily involved in proposing a standard set of eDiscovery activity codes for the ABA’s Uniform Task Based Management System (UTBMS) series of codes used to classify the legal services performed by a law firm in an electronic invoice submission.
Now, we need your help for an information gathering exercise.
We are currently conducting a Metrics Privilege survey to get a sense throughout the industry as to typical volumes and percentages of privileged documents within a collection. It’s a simple, 7 question survey that strives to gather information regarding your experiences with privileged documents (whether you work for a law firm, corporation, provider or some other organization).
If you have a minute (which is literally all the time it will take), please take the survey and pass along to your colleagues to do so as well. The more respondents who participate, the more representative the survey will be as to the current eDiscovery community. To take the survey, go to edrm.net or click here. EDRM will publish the results in the near future.
So, what do you think? What are your typical metrics with regard to privileged documents? Please share any comments you might have or if you’d like to know more about a particular topic.