Export Files and Custom Content Images in FTK Imager – eDiscovery Best Practices
Over the past few weeks, we have talked about the benefits and capabilities of Forensic Toolkit (FTK) Imager from AccessData (and obtaining your own free copy), how to create a disk image and how to add evidence items with FTK Imager for the purpose of reviewing the contents of evidence items, such as physical drives or images that you’ve created. This week, let’s discuss how to export files and how to create a custom content image of a targeted collection of files.
Sometimes, you don’t want to create an image of the entire drive; instead, you’d like to perform a targeted collection or export individual files to review them. Let’s discuss how to do that.
Export Files
As we discussed last time, you can Add Evidence Item to add a single evidence item to the evidence tree. You can select a Physical Drive or Logical Drive, an Image File to view an image file created before or Contents of a Folder, to look at a specific folder. You can also Add All Attached Devices to add all of the attached physical and logical devices. When you select one or more evidence items, the selected items will be displayed in the Evidence Tree on the left hand side; navigate to the folder you want and it will display the contents on the right hand side.
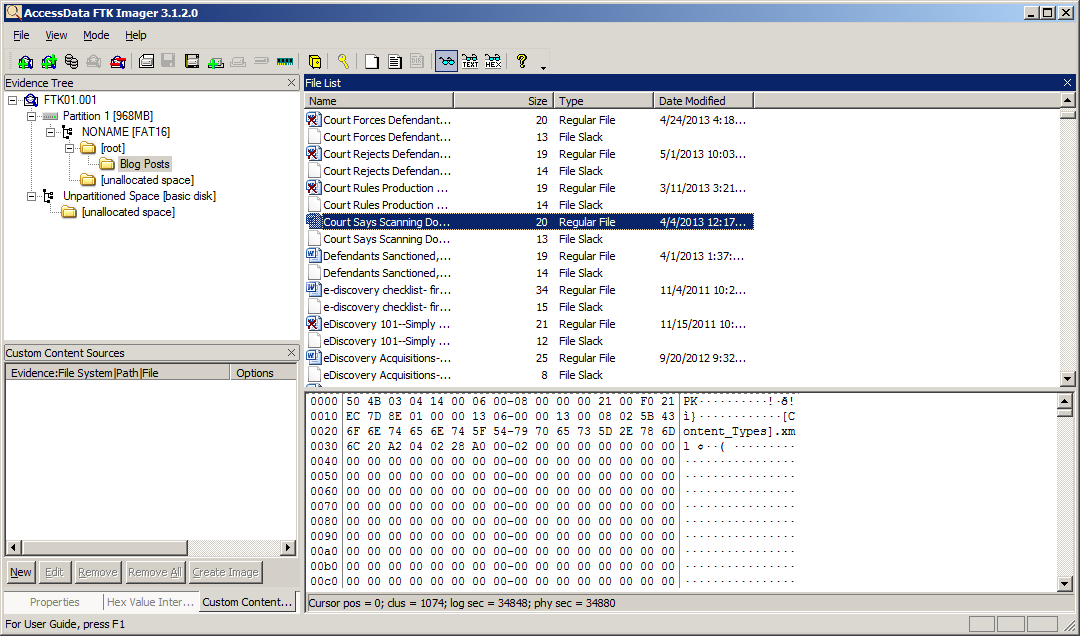
Select one or more files (use Ctrl+Click to select multiple files or Shift+Click to select a range of files), then right-click on one of the files to display a popup menu.
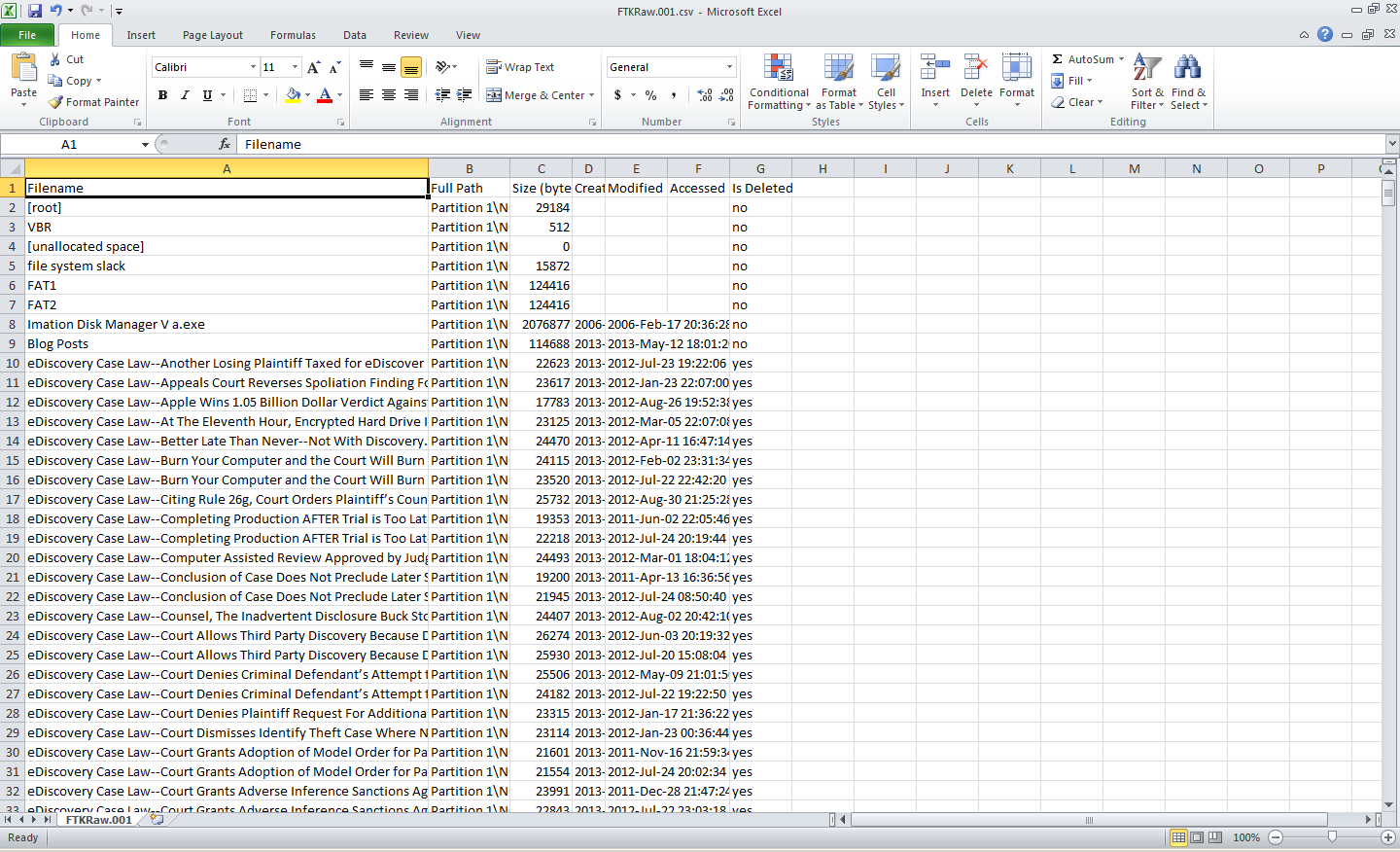
Select Export Files to export the selected files, then FTK Imager will prompt you for a folder where the files will be saved. The files will be saved to that folder. Exporting files can be useful to pull a copy of selected files out of a forensic image for review.
Create Custom Content Image
As you’ll notice in the previous section, when you display the popup menu, another choice is to Add to Custom Content Image (AD1). This enables you to start building a targeted list of files to be included in a custom image – useful if you want a specific group of files and not everything on the evidence item.
Any files that you select will then be added to the Custom Content Sources pane in the lower left window. Continue adding items by repeating this step until you’ve specified or selected all the evidence files you want to add to this Custom Content image. You can also use the Edit button to open the Wild Card Options dialog and select all files that meet a certain criteria (e.g., “My Documents|*.doc” will collect all files with a .doc extension in any folder named My Documents).
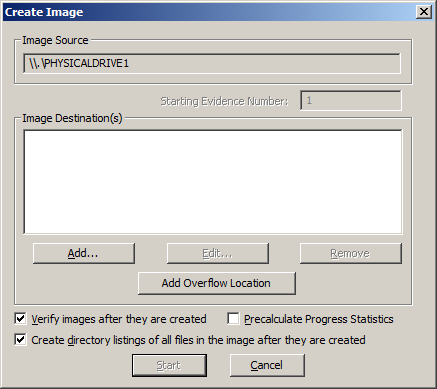
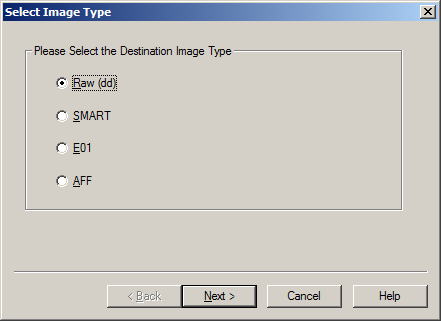
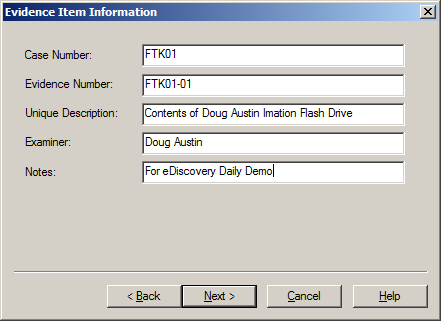
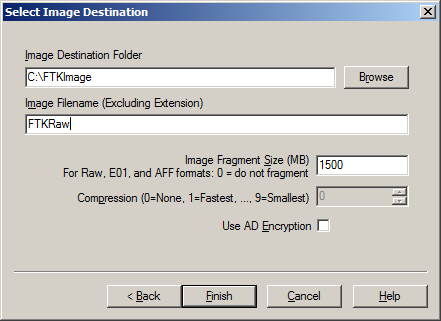
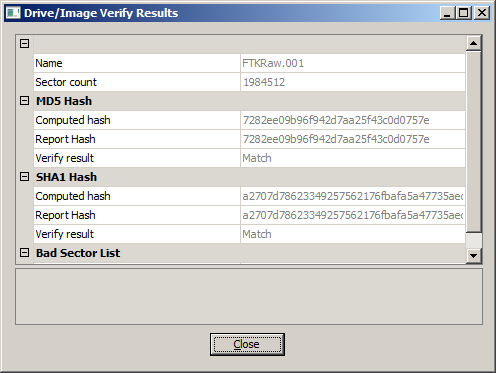
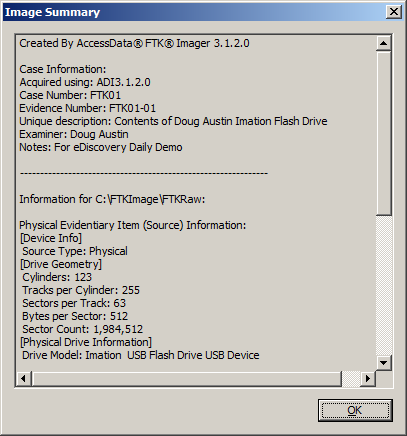
Once you have built your desired list of files, you can then build your Custom Content Image. Select Create Custom Content Image from the file menu. You can then repeat the steps for the Create Image, Evidence Item Information, Select Image Destination, Drive/Image Verify Results and Image Summary forms as illustrated in our earlier post How to Create an Image Using FTK Imager. The resulting image will have an AD1 extension. Then, this image can be examined just like any other image.
For more information, go to the Help menu to access the User Guide in PDF format.
Next time, we will discuss how to Obtain Protected Files to collect a user’s account information and possible passwords to other files.
So, what do you think? Have you used FTK Imager as a mechanism for eDiscovery collection? Please share any comments you might have or if you’d like to know more about a particular topic.
Disclaimer: The views represented herein are exclusively the views of the author, and do not necessarily represent the views held by CloudNine Discovery. eDiscoveryDaily is made available by CloudNine Discovery solely for educational purposes to provide general information about general eDiscovery principles and not to provide specific legal advice applicable to any particular circumstance. eDiscoveryDaily should not be used as a substitute for competent legal advice from a lawyer you have retained and who has agreed to represent you.