More Updates from the EDRM Annual Meeting – eDiscovery Trends
Yesterday, we discussed some general observations from the Annual Meeting for the Electronic Discovery Reference Model (EDRM) group and discussed some significant efforts and accomplishments by the (suddenly heavily talked about) EDRM Data Set project. Here are some updates from other projects within EDRM.
It should be noted these are summary updates and that most of the focus on these updates is on accomplishments for the past year and deliverables that are imminent. Over the next few weeks, eDiscovery Daily will cover each project in more depth with more details regarding planned activities for the coming year.
Model Code of Conduct (MCoC)
The MCoC was introduced in 2011 and became available for organizations to subscribe last year. To learn more about the MCoC, you can read the code online here, or download it as a 22 page PDF file here. Subscribing is easy! To voluntarily subscribe to the MCoC, you can register on the EDRM website here. Identify your organization, provide information for an authorized representative and answer four verification questions (truthfully, of course) to affirm your organization’s commitment to the spirit of the MCoC, and your organization is in! You can also provide a logo for EDRM to include when adding you to the list of subscribing organizations. Pending a survey of EDRM members to determine if any changes are needed, this project has been completed. Team leaders include Eric Mandel of Zelle Hofmann, Kevin Esposito of Rivulex and Nancy Wallrich.
Information Governance Reference Model (IGRM)
The IGRM team has continued to make strides and improvements on an already terrific model. Last October, they unveiled the release of version 3.0 of the IGRM. As their press release noted, “The updated model now includes privacy and security as primary functions and stakeholders in the effective governance of information.” IGRM continues to be one of the most active and well participated EDRM projects. This year, the early focus – as quoted from Judge Andrew Peck’s keynote speech at Legal Tech this past year – is “getting rid of the junk”. Project leaders are Aliye Ergulen from IBM, Reed Irvin from Viewpointe and Marcus Ledergerber from Morgan Lewis.
Search
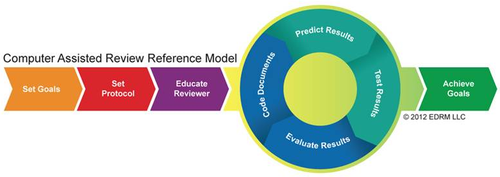
One of the best examples of the new, more agile process for creating deliverables within EDRM comes from the Search team, which released its new draft Computer Assisted Review Reference Model (CARRM), which depicts the flow for a successful Computer Assisted Review project. The entire model was created in only a matter of weeks. Early focus for the Search project for the coming year includes adjustments to CARRM (based on feedback at the annual meeting). You can also still send your comments regarding the model to mail@edrm.net or post them on the EDRM site here. A webinar regarding CARRM is also planned for late July. Kudos to the Search team, including project leaders Dominic Brown of Autonomy and also Jay Lieb of kCura, who got unmerciful ribbing for insisting (jokingly, I think) that TIFF files, unlike Generalissimo Francisco Franco, are still alive. 🙂
Jobs
In late January, the Jobs Project announced the release of the EDRM Talent Task Matrix diagram and spreadsheet, which is available in XLSX or PDF format. As noted in their press release, the Matrix is a tool designed to help hiring managers better understand the responsibilities associated with common eDiscovery roles. The Matrix maps responsibilities to the EDRM framework, so eDiscovery duties associated can be assigned to the appropriate parties. Project leader Keith Tom noted that next steps include surveying EDRM members regarding the Matrix, requesting and co-authoring case-studies and white papers, and creating a short video on how to use the Matrix.
Metrics
In today’s session, the Metrics project team unveiled the first draft of the new Metrics model to EDRM participants! Feedback was provided during the session and the team will make the model available for additional comments from EDRM members over the next week or so, with a goal of publishing for public comments in the next two to three weeks. The team is also working to create a page to collect Metrics measurement tools from eDiscovery professionals that can benefit the eDiscovery community as a whole. Project leaders Dera Nevin of TD Bank and Kevin Clark noted that June is “budget calculator month”.
Other Initiatives
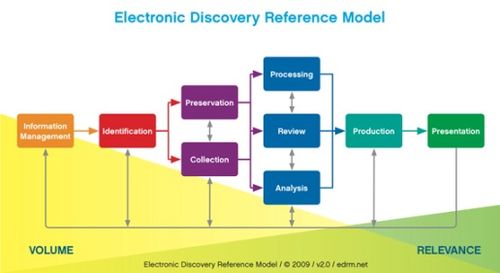
As noted yesterday, there is a new project to address standards for working with native files in the different EDRM phases led by Eric Mandel from Zelle Hofmann and also a new initiative to establish collection guidelines, spearheaded by Julie Brown from Vorys. There is also an effort underway to refocus the XML project, as it works to complete the 2.0 version of the EDRM XML model. In addition, there was quite a spirited discussion as to where EDRM is heading as it approaches ten years of existence and it will be interesting to see how the EDRM group continues to evolve over the next year or so. As you can see, a lot is happening within the EDRM group – there’s a lot more to it than just the base Electronic Discovery Reference Model.
So, what do you think? Are you a member of EDRM? If not, why not? Please share any comments you might have or if you’d like to know more about a particular topic.
Disclaimer: The views represented herein are exclusively the views of the author, and do not necessarily represent the views held by CloudNine Discovery. eDiscoveryDaily is made available by CloudNine Discovery solely for educational purposes to provide general information about general eDiscovery principles and not to provide specific legal advice applicable to any particular circumstance. eDiscoveryDaily should not be used as a substitute for competent legal advice from a lawyer you have retained and who has agreed to represent you.