When a Text File Doesn’t Match the Image or Native Excel File, What Do You Do?: eDiscovery Best Practices
Even when you’ve been in the business for 25+ years, you sometimes encounter situations you can’t explain (at least initially). Here is a story about a document that I encountered yesterday that initially didn’t make sense to me. Thankfully, I’m extremely curious and ultimately figured it out (with some help). See if it will be obvious to you.
The Issue
In a document collection produced by the opposing party to our client (where we received agreed upon images, text files, native files and metadata), I was performing searches in our CloudNine review platform looking for documents related to a key investment account disputed between the two parties. On one of the documents, I found a hit in the searchable text referencing key information related to the account that was noted by an accountant that we had not yet previously encountered. This appeared to be an important document.
To get a better look at the document, I decided to look at the image that was provided. That text entry was not there.
Since we had the produced Excel file, I downloaded a copy of it (from CloudNine) to take a look at it and the text did not appear to be present in the original native Excel file either. When I performed a search for the accountant’s last name in the entire workbook, Excel retrieved no hits.
What? How can that be?
Figuring It Out
My first thought was that there were hidden columns, rows or worksheets within the Excel file that were not being searched. As it turned out, there was one hidden sheet (which I unhid), but repeating my search for the accountant’s last name in the entire workbook still retrieved no hits.
At this point, I’m wondering if the opposing party may have doctored the image and the Excel file, but forgot to doctor the produced extracted text? You hate to believe the worst of people, but it happens.
Out of ideas, I took the issue to CloudNine’s production manager, Jesus Arellano. After he looked at the Excel file and performed the same search (finding nothing, which made me feel better), he then decided to perform a text extract of the Excel file using LAW PreDiscovery® (which was later reproduced with our own CloudNine Discovery Client processing software). We looked at the results in the text and, behold, there was the note from the accountant!
What the hell is going on out here?
Finally, The Answer
Taking another look at the Excel file, we finally noticed that little red triangle in the corner of some of the cells. Excel comments. Of course.
When I put the cursor over the cell, the comment popped up, revealing the note (that should have been a clue) from the accountant. Excel comments aren’t normally displayed unless you put the cursor on the cell where the comment is contained (you can show all comments under the review tab, but hardly anybody ever does). When the Excel is “printed” to an image file, only the main portion of the workbook is “printed”, not the hidden comments. The same is true for other Microsoft Office applications, as well. So, don’t expect to typically see the hidden comments in an image of an Excel workbook, Word document or other Office file.
As for searching the hidden comments in Excel, you can do so using Ctrl+F, you just have to make sure you change the “Look in” field to Comments to search those specifically (see the example below using my last name of Austin):
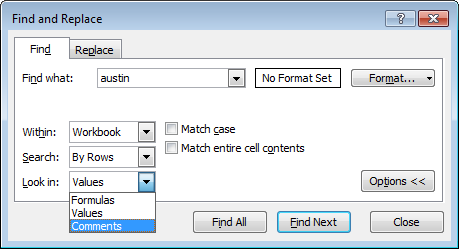
Perhaps, if it hadn’t been at the end of a long day, I would have caught it more quickly (that’s my excuse, anyway). Nonetheless, it serves as an excellent example of how hidden metadata can contain important information. Due to this find, resulting from the original text search I did, we identified an individual for our client to depose!
So, what do you think? Have you ever encountered data important to a case in the hidden metadata of a file? Please share any comments you might have or if you’d like to know more about a particular topic.
Disclaimer: The views represented herein are exclusively the views of the author, and do not necessarily represent the views held by CloudNine. eDiscovery Daily is made available by CloudNine solely for educational purposes to provide general information about general eDiscovery principles and not to provide specific legal advice applicable to any particular circumstance. eDiscovery Daily should not be used as a substitute for competent legal advice from a lawyer you have retained and who has agreed to represent you.